

Für MSP’s und Systemhäuser sind Überwachung und Benachrichtigung von zentraler Bedeutung für die von Ihnen angebotenen Dienstleistungen. Gute Überwachungspraktiken ermöglichen es Ihnen, Probleme proaktiv zu erkennen, sie schneller zu lösen und wirkungsvoller zu arbeiten. Besseres Monitoring kann auch eine Schlüsselrolle bei der Generierung zusätzlicher Einnahmen spielen und die Kundenzufriedenheit steigern.
Die Herausforderung besteht darin zu wissen, was man überwachen muss, wann eine Benachrichtigung erforderlich ist, welche Aufgaben automatisiert gelöst werden können und wann persönliches Eingreifen erforderlich ist. Es kann Jahre dauern, bis man sich dieses Wissen erworben hat und selbst dann passiert es den besten Teams noch, dass sie im Hintergrundrauschen zu vieler Benachrichtigungen und Tickets den Blick aufs wesentliche verlieren.
Wir haben diese Liste mit Empfehlungen für mehr als 25 zu überwachende Bedingungen zusammengestellt, damit diejenigen, die noch am Anfang dieses Optimierungsprozesses stehen, schneller ans Ziel kommen und sich auf die wichtigen Aspekte fokussieren können. Diese Empfehlungen basieren auf Vorschlägen unserer Partner und auf den Erfahrungen, die NinjaOne durch die Unterstützung seiner Partner im Aufbau effektiver und praktikabler Monitoring-Prozesse gesammelt hat.
So verwenden Sie die nachfolgenden Checklisten
Für jede Bedingung beschreiben wir, was überwacht wird, wie Sie das NinjaOne-Monitoring einrichten können und welche Maßnahmen erfolgen sollten, sobald die Bedingung ausgelöst wurde. Einige Vorschläge für die Überwachung sind konkreter Natur, während andere einen geringen Anpassungsaufwand erfordern, damit sie Ihren Bedürfnissen gerecht werden.
Hinweis: Die Monitoring-Empfehlungen sind problemlos auch auf andere RMM’s übertragbar.
Sobald Sie Ihr Monitoring mit Hilfe dieser Empfehlungen gestartet haben, sollten Sie eine individuellere Überwachungsstrategie entwickeln, die auf Ihre Kunden und deren Bedürfnissebasiert. Am Ende dieses Artikels finden Sie zusätzliche Ratschläge, mit denen Sie Ihre Überwachung, Benachrichtigungen und Ticketausstellung zu einem echten Wettbewerbsvorteil für Ihr MSP-Unternehmen ausbauen können.
Checkliste zur Überwachung des Gerätezustands

Überwachung auf gehäufte kritische Ereignisse
- Bedingung: Kritische Ereignisse
- Schwellenwert: 80 kritische Ereignisse innerhalb von 5 Minuten
- Maßnahme: Ticket und Fehlersuche
Feststellung nicht beabsichtigter Neustarts von Geräten
- Bedingung: Windows-Ereignis
- Ereignis-Quelle: Microsoft-Windows-Kernel-Power
- Ereignis-ID: 41
- Anmerkung: Die Bedingung eignet sich besser für Server, da dieses Ereignis auf Workstations und Laptops durch Handlungen der Benutzer ausgelöst werden kann.
- Maßnahme: Ticket- und Fehlersuche
Geräte identifizieren, die einen Neustart benötigen
- Bedingung: System-Aktivitätszeit
- Empfohlener Schwellenwert: 30 oder 60 Tage
- Maßnahme: Starten Sie das Gerät während eines geeigneten Zeitfensters neu. Für Workstations kann eine Automatisierung eingerichtet werden.
Überwachung auf Offline-Endpunkte
- Bedingung: Gerät außer Betrieb
- Empfohlener Schwellenwert:
- 10 Minuten oder weniger (Server)
- 24+ Stunden (Workstations)
- Maßnahmen:
- Ticket und Fehlersuche
- Wake-on-lan (nur bei Servern)
Überwachung bei Änderungen der Hardware
- Aktivität: System
- Schwellenwert: Adapter hinzugefügt/geändert, CPU hinzugefügt/geändert, Laufwerk hinzugefügt/entfernt, Memory hinzugefügt/entfernt
- Maßnahme: Ticket und Nachforschungen
Checkliste zur Überwachung von Laufwerken
Überwachung potenzieller Festplattenfehler
- Bedingung: Windows S.M.A.R.T. Status verschlechtert
und/oder - Bedingung: Windows-Ereignis
- Ereignis-Quelle: Festplatte
- Ereignis-ID’s: 7, 11, 29, 41, 51, 153
- Maßnahmen: Ticket und Nachforschungen
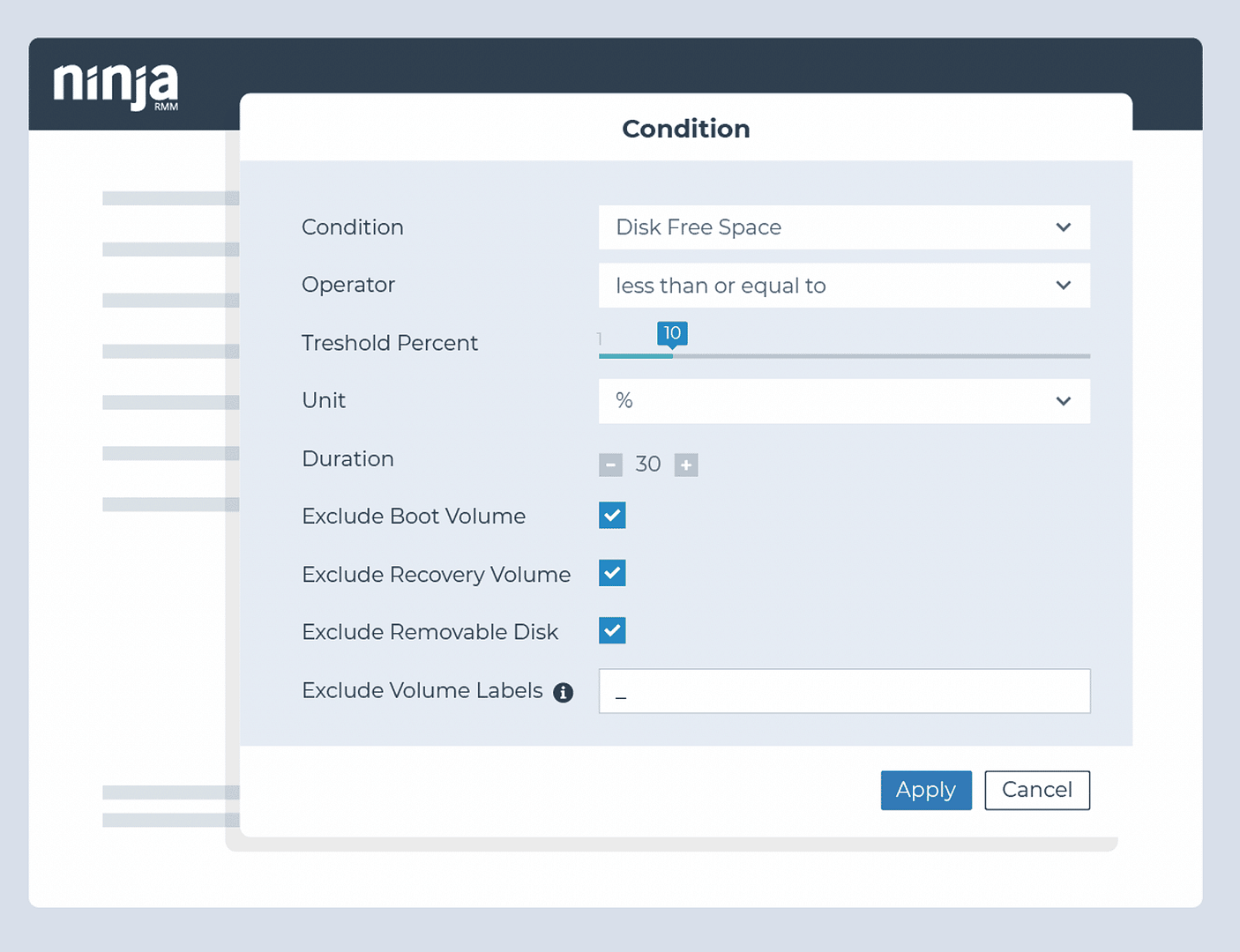
Überwachung der Kapazitätsgrenze des Festplattenspeichers
- Bedingung: Freier Speicherplatz auf Festplatten
- Schwellenwert: jeweils bei 20% und 10%
- Maßnahmen: Festplattenbereinigung und Löschen temporärer Dateien
Überwachung potenzieller RAID-Fehler
- Bedingung: RAID-Integritätsstatus
- Schwellenwerte: kritisch und unkritisch bei allen Attributen
- Maßnahmen: Ticket and Nachforschungen
Überwachung auf anhaltende Datenträgerverwendung
- Bedingung: Datenträgerverwendung
- Schwellenwerte: 90% oder höher (um unnötige Benachrichtigungen auszuschließen), über 95% sind auch in Ordnung für einen Zeitraum von weniger als 30 oder 60 Minuten
- Maßnahmen: Ticket and Nachforschungen
Überwachung auf erhöhte Festplattenaktivität
- Bedingung: Aktive Datenträgerzeit
- Schwellenwerte: Über 90% für 15 Minuten
- Maßnahmen: Ticket und Nachforschungen
Überwachung auf erhöhte Speicherauslastung
- Bedingung: Aktive Datenträgerzeit
- Schwellenwerte: Über 90% innerhalb von 15 Minuten
- Action: Ticket und Nachforschungen

Checkliste zur Überwachung von Anwendungen
![]()
Sind alle relevanten Anwendungen auf einem Endpunkt vorhanden?
- Bedingung: Software
- Verwendung für:
- Kundenspezifische Geschäftsanwendungen (Beispiele: AutoCAD, SAP, Photoshop)
- Kundenspezifische Produktivitätsanwendungen (Beispiele: Zoom, Microsoft Teams, DropBox, Slack, Office, Acrobat)
- Werkzeuge für den Kundensupport (Beispiele: TeamViewer, CCleaner, AutoElevate, BleachBit)
- Maßnahmen: Automatisierte Installation von erforderlichen Anwendungen, falls sie nicht vorhanden sind
Überwachen, ob kritische Anwendungen ausgeführt werden (insbesondere für Server)
- Bedingung: Prozess / Service
- Schwellenwert: Ausfallzeit mindestens 3 Minuten
- Beispielhafte Prozesse:
- Für Workstations: TeamViewer, RDP, DLP
- Für Exchange Server: MSExchangeServiceHost, MSExchangeIMAP4, MSExchangePOP3, etc
- Für einen Active Directory Server: Netlogon, dnscache, rpcss, etc
- For einen SQL Server: mssqlserver, sqlbrowser, sqlwriter, etc
- Maßnahmen: Service oder Prozess neustarten
Überwachung der Ressourcennutzung für Anwendungen, die bekanntermaßen Performance-Probleme verursachen
- Bedingung: Prozessressource
- Schwellenwert: über 90% für mindestens 5 Minuten
- Beispielhafte Prozesse: Outlook, Chrome und TeamViewer
- Maßnahmen:
- Ticket and Nachforschungen
- Ausführen bei Systemstart sperren
Überwachung auf Abstürze von Anwendungen
- Bedingung: Windows-Ereignis
- Ereignis-Quelle: Anwendung reagiert nicht
- Ereignis-ID: 1002
- Maßnahme: Ticket und Nachforschungen
Netzwerk Monitoring Checkliste
![]()
Überwachung auf unerwartete Bandbreitenauslastung
- Bedingung: Netzwerkauslastung
- Richtung: Out
- Schwellenwerte: Die Schwellenwerte richten sich nach der Art des Endpunkts und der Netzwerkkapazität
- Für jeden Server sollten angepasste Schwellenwerte festgelegt werden
- Die Schwellenwerte der Netzwerk-Überwachung für Workstations sollten hoch genug liegen, so dass Benachrichtigungen erst ausgelöst werden, wenn ein Kundennetzwerk gefährdet ist
- Maßnahmen: Ticket and Nachforschungen
Sicherstellen, dass Netzwerkgeräte verfügbar sind
- Bedingung: Gerät reagiert nicht
- Dauer: 3 Minuten
Überwachung offener Ports
- Bedingung: Cloud-Monitor
- Ports: 80 (HTTP), 443 (HTTPS), 25 (SMTP), 21 (FTP)
Überwachung der Verfügbarkeit von Kunden-Internetseiten
- Monitor: Ping
- Ziel: Kunden-Internetauftritt
- Bedingung: Verbindungsfehler (5 mal)
- Maßnahmen: Ticket und Fehlersuche
Checkliste für die grundlegende Sicherheitsüberwachung
Benachrichtigung sobald die Windows-Firewall deaktiviert wird
- Bedingung: Windows-Ereignis
- Ereignis-Quelle: System
- Ereignis-ID: 5025
- Maßnahmen: Aktivierung der Windows-Firewall
Feststellen, ob Antivirus- und Sicherheitswerkzeuge auf einem Endpunkt installiert sind und/oder ausgeführt werden
- Bedingung: Software
- Anwesenheit: existiert nicht
- Software (Beispiele): Huntress, Cylance, Threatlocker, Sophos
- Maßnahme: Automatisieren Sie die Installation der fehlenden Sicherheits- und Antivirus-Software
- Bedingung: Prozess / Service
- Zustand: läuft nicht
- Prozess (Beispiele): threatlockerservice.exe, EPUpdateService.exe
- Maßnahme: Prozess neustarten/li>
Überwachung nicht nativ integrierter AV / durch EDR erkannter Gefährdungen
- Bedingung: Windows-Ereignis
- Beispiel: (Sophos)
- Ereignis-Quelle: Sophos Anti-Virus
- Ereignis-ID’s: 6, 16, 32, 42
Überwachung auf gescheiterte Anmeldeversuche von Benutzern
- Bedingung: Windows-Fehler
- Ereignis-Quelle: Microsoft-Windows-Security-Auditing
- Event-ID’s: 4625, 4740, 644 (Lokale Accounts); 4777 (Domain Login)
- Maßnahmen: Ticket und Nachforschungen
Überwachung von hinzugefügten, gelöschten oder höher gestuften Benutzerkonten auf Endpunkten
- Bedingung: Windows-Fehler
- Ereignisquelle: Microsoft-Windows-Security-Auditing
- Ereignis ID: 4720, 4732, 4729
- Maßnahme: Ticket und Nachforschungen
Überwachen ob Laufwerke auf Endpunkten verschlüsselt oder unverschlüsselt sind
- Bedingung: Skriptausgabe
- Skript (benutzerdefiniert): Überprüfung des Verschlüsselungs-Status
- Maßnahme: Ticket und Nachforschungen
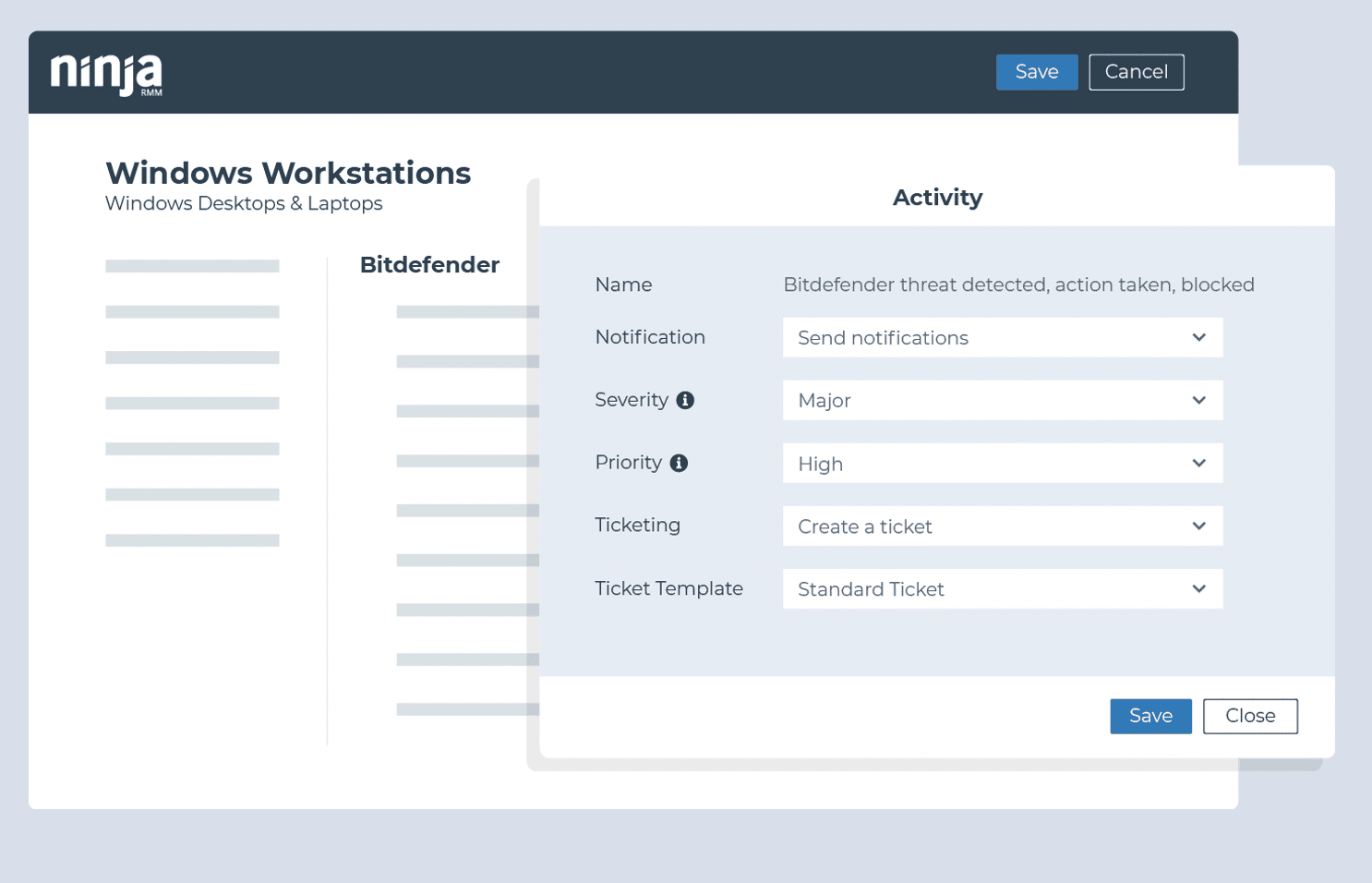
Überwachen von Backup-Versagen (Ninja Data Protection)
- Aktivität: Ninja Data Protection
- Name: Backup-Job failed
Überwachen von Backup-Versagen (andere Backup-Anbieter)
- Bedingung: Windows-Ereignis
- Beispiel-Quelle / ID‘s (Veeam):
- Ereignis-Quelle: Veeam Agent
- Ereignis-ID: 190
- Text enthält: [failed]
- Beispiel-Quelle / ID‘s (Acronis):
- Ereignis-Quelle: Online Backup System
- Ereignis-ID: 1
- Text enthält: [failed]
4 Profi-Tipps für ein noch besseres Monitoring
- Erstellen Sie sich eine Generalvorlage zur Überwachung des Gerätezustands.
- Sprechen Sie mit Ihren Kunden über deren Prioritäten.
- Welche Server und Workstations sind die wichtigsten?
- Welches sind Ihre wichtigsten Geschäfts- und Produktivitätsanwendungen?
- Wo liegen ihre IT-Schmerzpunkte/Problemfelder?
- Überwachen Sie Ihr PSA / Ticketing-System auf wiederkehrende Probleme.
- Passen Sie Benachrichtigungen dementsprechend an, um unnötige Mitteilungen zu vermeiden.
- Überwachen Sie die Event-Logs Ihrer Kunden auf wiederkehrende Probleme
Ticketing & Benachrichtigungen: Hilfreiche Beispiele
- Überwachen Sie nur auf Informationen, die wirklich verwertbar sind. Falls Sie für eine Überwachung keine bestimmte Reaktion formulieren können, sollten Sie die Überwachung einstellen.
- Kategorisieren Sie Ihre Benachrichtigungen, so dass diese je nach Sachverhalt und Priorität an unterschiedliche Service-Boards in Ihrem PSA weitergeleitet werden.
- Setzen Sie Meetings zum Thema Benachrichtigungs-Management an und besprechen Sie gemeinsam folgende Fragen:
-
- Gibt es Benachrichtigungen, die überhand nehmen? Könnte man diese vielleicht reduzieren oder auf relevante Fälle eingrenzen?
- Was wird bisher nicht überwacht, sollte aber definitiv zu Benachrichtigungen an Ihr Team führen?
- Welche häufig auftretenden Benachrichtigungen können mittels Automatisierung bearbeitet werden?
- Gibt es Projekte, die in naher Zukunft zu Fehlern und Benachrichtigungen führen könnten?
- Tickets und Benachrichtigungen nach dem Bearbeiten ad acta legen
-
- In NinjaOne gibt es für viele Bedingungen die Option: “Zurücksetzen, sobald nicht mehr erfüllt” oder “Zurücksetzen, sobald nicht mehr erfüllt für ”. Benachrichtigungen, deren Grundlage bereits behoben wurde sind somit vom Tisch.
Sie suchen weitere hilfreiche MSP Überwachungsanleitungen?
Kelvin Tegelaar bietet dazu eine exzellente, englischsprachige Serie zum Thema Remote Monitoring using PowerShell. Er erläutert, wie man alles Mögliche überwacht, vom Netzwerkverkehr über den Zustand der Active Directory bis hin zu fehlgeschlagenen Office 365-Anmeldungen, Shodan-Ergebnissen und mehr. Das Beste ist, dass er auf RMM’s ausgelegte PowerShell-Skripte mit Ihnen teilt.
Daher ist er auch oft Bestandteil unseres englischsprachigen MSP-Bento Newsletters, in dem wir Ihnen wöchentlich viele Werkzeuge und Ressourcen empfehlen. Melden Sie sich hier an und Sie erhalten direkt die letzte Ausgabe und die beliebtesten Tools und Ressourcen, die wir für Sie zusammengestellt haben.
[/av_textblock]






