

Als MSP staan monitoring en alerting centraal in de diensten die u levert. Met goede monitoringpraktijken kunt u proactief problemen opsporen, ze sneller oplossen en doeltreffender werken. Betere monitoring kan ook een belangrijke rol spelen bij het genereren van extra inkomsten en bij uw klanten nog tevredener houden.
De uitdaging is weten waarop u moet letten, waarvoor een waarschuwing nodig is, welke problemen automatisch kunnen worden opgelost en welke een persoonlijke aanpak vereisen. Die kennis duurt jaren om te ontwikkelen en zelfs dan kunnen de beste teams nog worstelen met de vele waarschuwingen en de ticketruis op alle clientapparaten.
We willen de aanlooptijd van mensen die net beginnen verkorten en hun focus gerichter maken. Daarom hebben we deze lijst met meer dan 25 voorwaarden om te monitoren samengesteld. Deze aanbevelingen zijn gebaseerd op de suggesties van onze partners en op de ervaringen van NinjaOne tijdens het helpen van MSP’s bij de opbouw van effectieve, actiegerichte monitoring.
Gebruik van de onderstaande checklists
Voor elke voorwaarde vindt u een beschrijving van wat er wordt gemonitord, hoe de monitoring in NinjaOne moet worden ingesteld en welke acties moeten worden ondernomen als de voorwaarde wordt geactiveerd. Sommige suggesties voor monitoring zijn concreet, terwijl andere misschien een kleine aanpassing vereisen voor ze passen bij uw gebruikssituatie.
Opmerking: we hebben deze checklist opgesteld met NinjaOne en onze klanten in het achterhoofd, maar deze ideeën voor monitoring kunnen ook makkelijk worden aangepast aan elk RMM-platform.
Deze lijst is uiteraard niet compleet en is wellicht niet op elke situatie of omstandigheid van toepassing.
Als u eenmaal aan de slag gaat met de opbouw van uw monitoring rond deze suggesties, ontwikkelt u best eert een aangepaste en robuustere monitoringstrategie, specifiek voor uw klanten en hun behoeften. We sluiten deze post af met aanvullende aanbevelingen ter ondersteuning van uw inspanningen zodat u van monitoring, alerting en een ticketsysteem een concurrentievoordeel maakt voor uw MSP.
Checklist voor monitoring van de conditie van apparaten

Monitor op doorlopende kritieke gebeurtenissen
- Voorwaarde: kritieke gebeurtenissen
- Drempel: 80 kritieke gebeurtenissen in 5 minuten
- Actie: ticket opstellen en onderzoeken
Identificeer wanneer een apparaat onbedoeld opnieuw wordt opgestart
- Voorwaarde: Windows-gebeurtenis
- Bron van de gebeurtenis: Microsoft-Windows-Kernel-Power
- Gebeurtenis-ID: 41
- Opmerking: deze voorwaarde is beter geschikt voor servers aangezien werkstations en laptops deze fout kunnen veroorzaken door tussenkomst van de gebruiker.
- Actie: ticket opstellen en onderzoeken
Identificeer apparaten die opnieuw opgestart moeten worden
- Voorwaarde: actieve tijd van het systeem
- Aanbeveling voor drempel: 30 of 60 dagen
- Actie: het apparaat opnieuw opstarten tijdens een geschikt tijdsvenster. Geautomatiseerd herstel kan werken voor werkstations.
Monitor op offline endpoints
- Voorwaarde: apparaat uit
- Aanbeveling voor drempel:
- 10 minuten of minder (servers).
- 24 uur of langer (werkstations)
- Actie:
- ticket opstellen en onderzoeken
- Wake-on-lan (alleen voor servers)
Monitor op veranderingen van de hardware
- Activiteit: systeem
- Naam: adapter toegevoegd/gewijzigd, CPU toegevoegd/verwijderd, schijfstation toegevoegd/verwijderd, geheugen toegevoegd/verwijderd
- Actie: ticket opstellen en onderzoeken
Checklist voor stationmonitoring
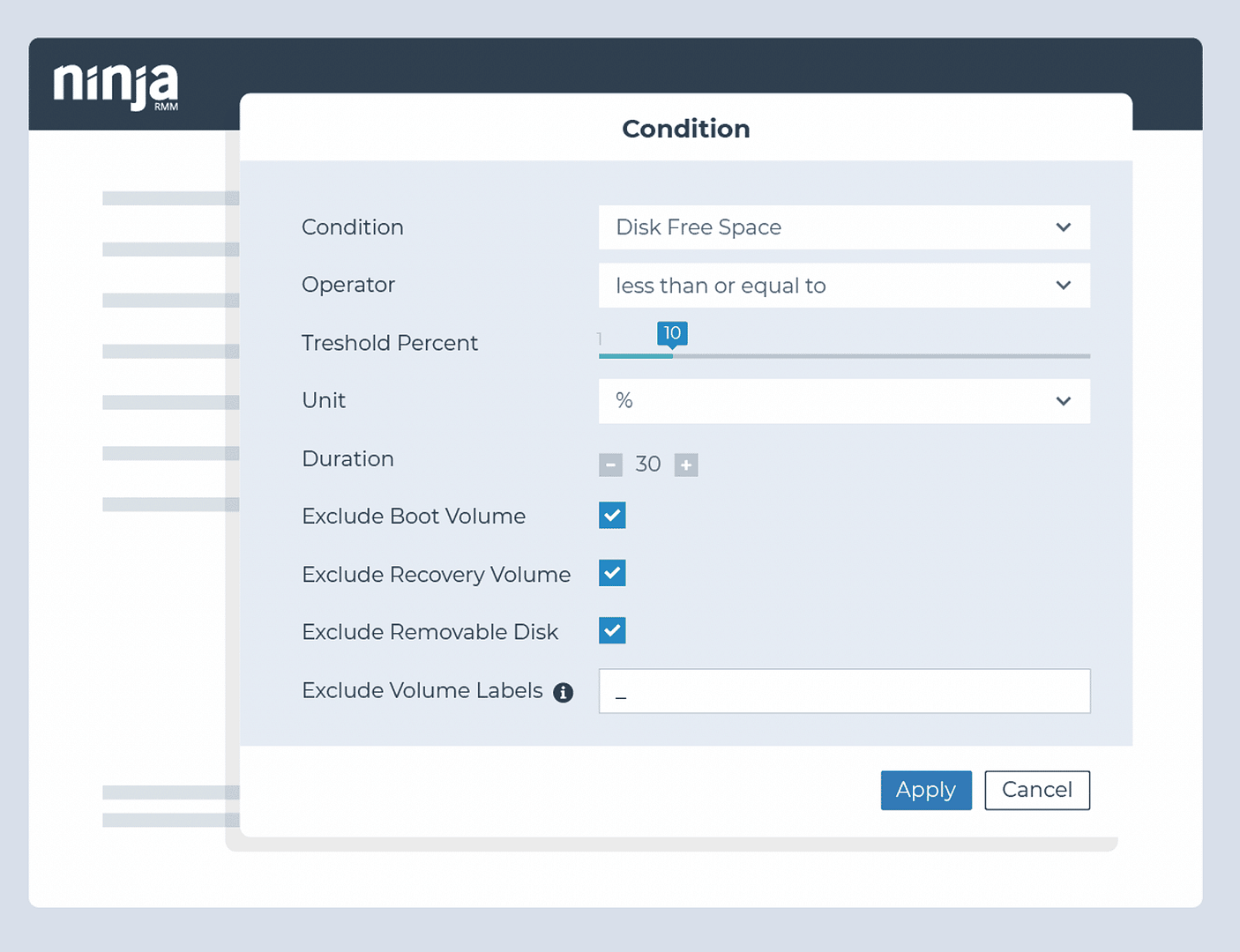
Monitor op mogelijke schijfstoringen
- Voorwaarde: Windows SMART-status verslechterd
en/of - Voorwaarde: Windows-gebeurtenis
- Bron van gebeurtenis: schijf
- Gebeurtenis-ID’s: 7, 11, 29, 41, 51, 153
- Actie: ticket opstellen en onderzoeken
Identificeer wanneer de schijfruimte volle capaciteit nadert
- Voorwaarde: vrije schijfruimte
- Drempel: 20% en opnieuw bij 10%
- Actie: schijf opruimen en tijdelijke bestanden verwijderen
Monitor op mogelijke RAID-storingen
- Voorwaarde: RAID-gezondheidsstatus
- Drempels: kritiek en niet-kritiek voor alle kenmerken
- Actie: ticket opstellen en onderzoeken
Monitor op langdurig hoog schijfgebruik
- Voorwaarde: schijfgebruik
- Drempels: 90% of meer om ruis te verminderen, waarbij meer dan 95% ook gebruikelijk is over perioden van 30 of 60 minuten
- Actie: ticket opstellen en onderzoeken
Monitor op percentage hoge schijfactiviteit
- Voorwaarde: actieve schijftijd
- Drempels: meer dan 90% gedurende 15 minuten
- Actie: ticket opstellen en onderzoeken
Monitor op hoog geheugengebruik
- Voorwaarde: actieve schijftijd
- Drempels: meer dan 90% gedurende 15 minuten
- Actie: ticket opstellen en onderzoeken
Checklist voor monitoringapplicaties
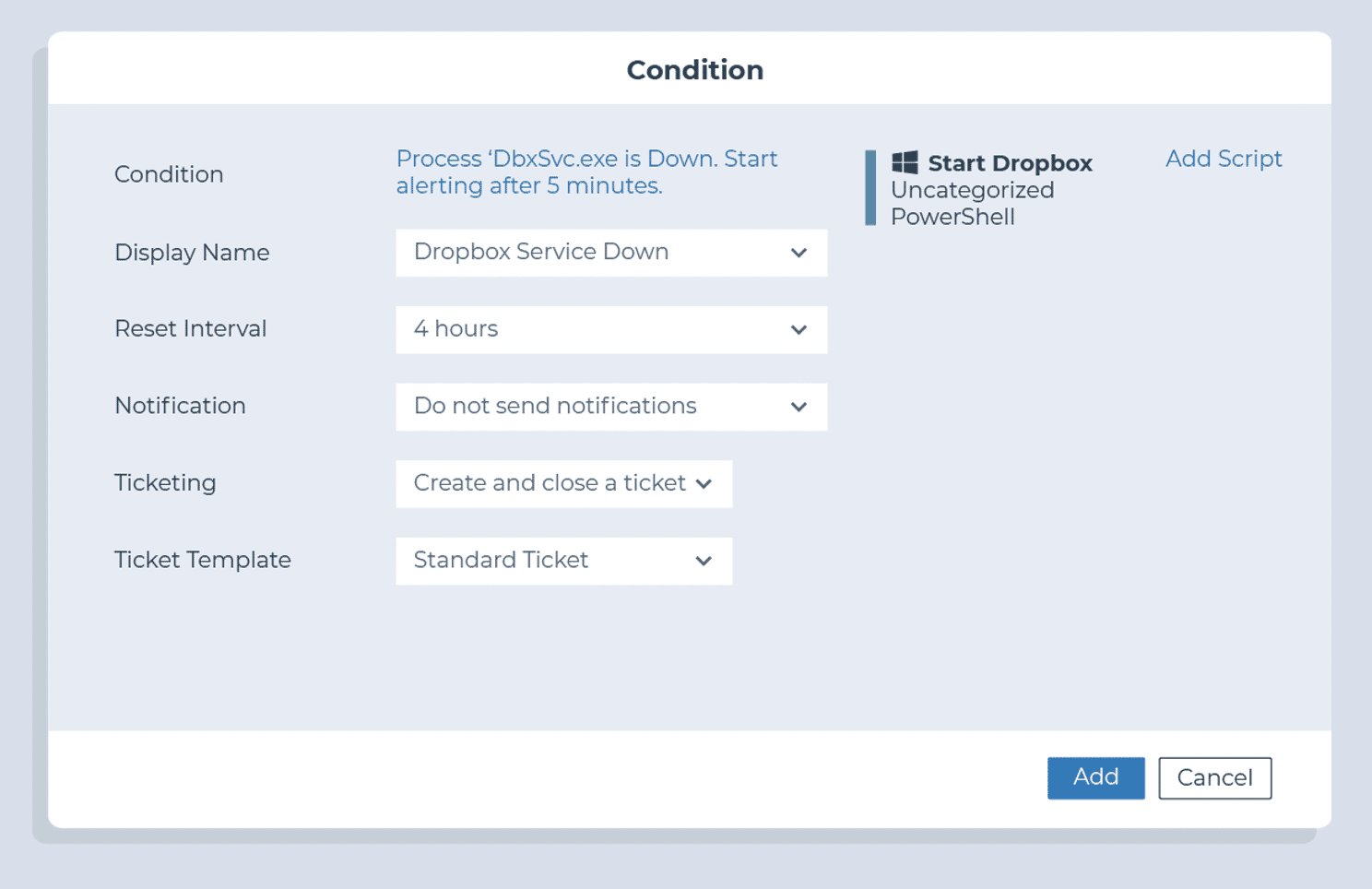
Identificeer of vereiste applicaties bestaan op een endpoint
- Voorwaarde: software
- Gebruik:
- Line-of-business klantapplicaties (voorbeelden: AutoCAD, SAP, Photoshop)
- Oplossingen voor klantproductiviteit (Voorbeelden: Zoom, Microsoft Teams, DropBox, Slack, Office, Acrobat)
- Hulpmiddelen voor klanten (Voorbeelden: TeamViewer, CCleaner, AutoElevate, BleachBit)
- Actie: de applicatie automatisch installeren als deze ontbreekt en vereist is
Monitor of kritieke applicaties worden uitgevoerd (met name voor servers)
- Voorwaarde: proces/service
- Drempel: minstens 3 minuten uit
- Voorbeeldprocessen:
- Voor werkstations: TeamViewer, RDP, DLP
- Voor een Exchange-server: MSExchangeServiceHost, MSExchangeIMAP4, MSExchangePOP3, etc.
- Voor een server met active directory: Netlogon, dnscache, rpcss, etc.
- Voor een SQL-server: mssqlserver, sqlbrowser, sqlwriter, etc.
- Actie: de service of het proces opnieuw opstarten
Monitor het gebruik van hulpbronnen voor applicaties waarvan bekend is dat ze prestatieproblemen veroorzaken
- Voorwaarde procesbron
- Drempel: meer dan 90% voor minstens 5 minuten
- Voorbeeldprocessen: Outlook, Chrome en TeamViewer
- Actie:
- ticket opstellen en onderzoeken
- uitschakelen bij opstart
Monitor op applicatiecrashes
- Voorwaarde: Windows-gebeurtenis
- Bron: applicatie loopt vast
- Gebeurtenis-ID: 1002
- Actie: ticket opstellen en onderzoeken
Checklist netwerkmonitoring

Monitor op onverwacht bandbreedtegebruik
- Voorwaarde: netwerkgebruik
- Richting: uit
- Drempel: drempelwaarden worden bepaald door het type endpoint en de netwerkcapaciteit
- Elke server moet zijn eigen drempel hebben op basis van de gebruikssituatie
- De drempels van de netwerkmonitoring van de werkstations moeten hoog genoeg zijn zodat ze alleen in werking treden als het netwerk van een klant gevaar loopt
- Actie: ticket opstellen en onderzoeken
Zorg dat de netwerkapparatuur werkt
- Voorwaarde: apparaat uit
- Duur: 3 minuten
Monitor welke poorten open zijn
- Voorwaarde: cloudmonitoring
- Poorten: 80 (HTTP), 443 (HTTPS), 25 (SMTP), 21 (FTP)
Monitor de beschikbaarheid van de klantwebsite
- Monitoring: ping
- Doel: klantwebsite
- Voorwaarde: storing (5 keer)
- Actie: ticket opstellen en onderzoeken
Checklist voor basismonitoring van de beveiliging
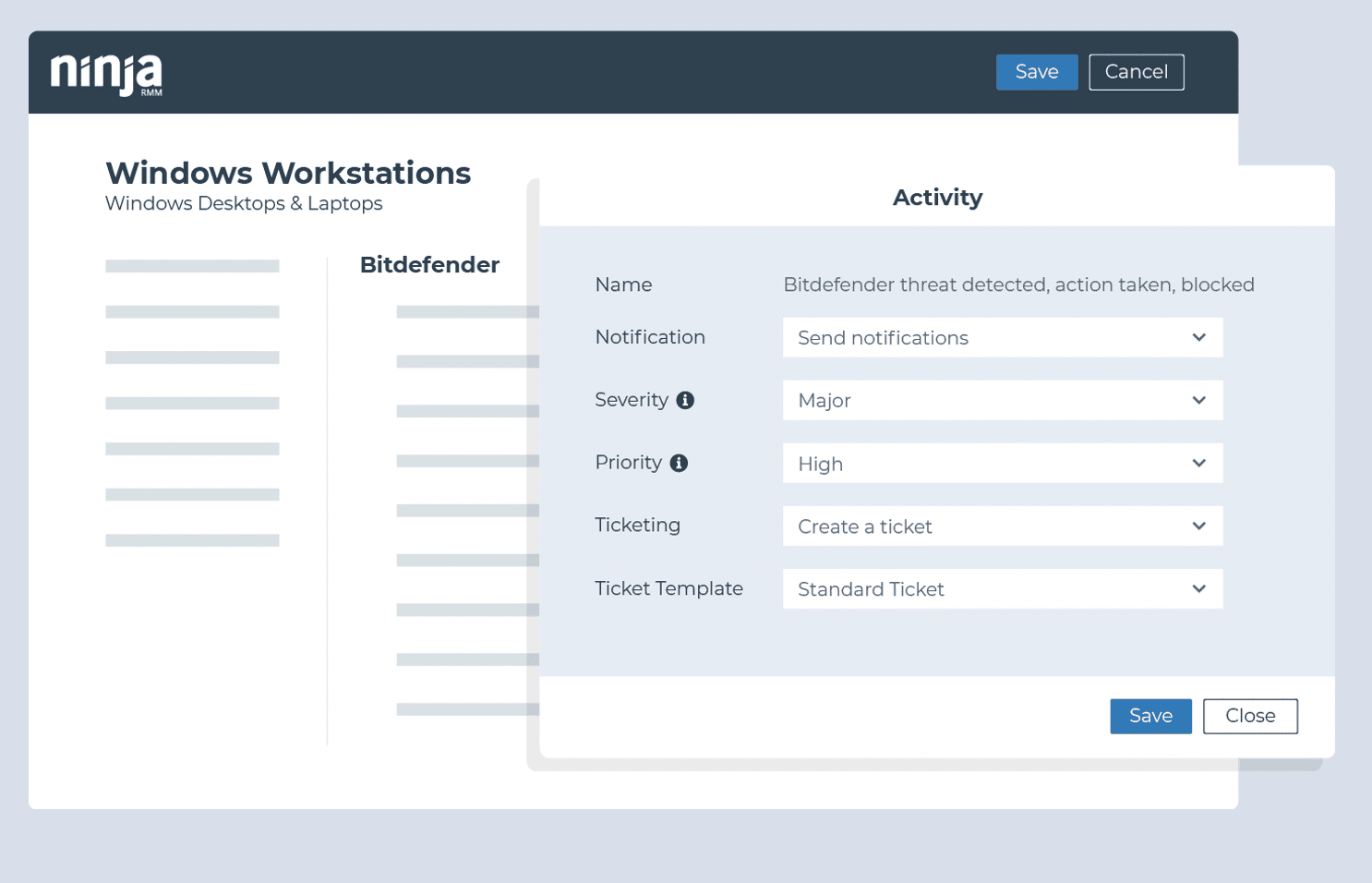
Identificeer of Windows Firewall is uitgeschakeld
- Voorwaarde: Windows-gebeurtenis
- Bron van gebeurtenis: systeem
- Gebeurtenis-ID: 5025
- Actie: Windows Firewall inschakelen
Identificeer of de antivirus- en beveiligingsprogramma’s zijn geïnstalleerd en/of actief zijn op een endpoint
- Voorwaarde: software
- Aanwezigheid: bestaat niet
- Software (voorbeelden): Huntress, Cylance, Threatlocker, Sophos
- Actie: de installatie van de ontbrekende beveiligingssoftware automatiserenen
- Voorwaarde: proces/service
- Status: uit
- Proces (voorbeelden): threatlockerservice.exe, EPUpdateService.exe
- Actie: het proces opnieuw opstarten
Monitor op gedetecteerde niet-geïntegreerde AV/EDR-bedreigingen
- Voorwaarde: Windows-gebeurtenis
- Voorbeeld (Sophos)
- Bron van gebeurtenis: antivirusprogramma van Sophos
- Gebeurtenis-ID’s: 6, 16, 32, 42
Monitor op mislukte inlogpogingen van gebruikers
- Voorwaarde: Windows-fout
- Bron van gebeurtenis: Microsoft-Windows-Beveiliging-Auditing
- Gebeurtenis-ID’s: 4625, 4740, 644 (lokale accounts); 4777 (domeinlogin)
- Actie: ticket opstellen en onderzoeken
Monitor op de creatie, bevordering of verwijdering van gebruikers op een endpoint
- Voorwaarde: Windows-fout
- Bron van gebeurtenis: Microsoft-Windows-Beveiliging-Auditing
- Gebeurtenis-ID: 4720, 4732, 4729
- Actie: ticket opstellen en onderzoeken
Identificeer of de stations op een endpoint versleuteld/niet-versleuteld zijn
- Voorwaarde:resultaat van script
- Script (Aangepast): controleer de versleutelingsstatus
- Actie: ticket opstellen en onderzoeken
Monitor op back-upfouten (Gegevensbescherming van Ninja)
- Activiteit: gegevensbescherming van Ninja
- Naam: back-uptaak mislukt
Monitor op back-upfouten (andere back-upleveranciers)
- Voorwaarde: Windows-gebeurtenis
- Voorbeeld van bron/ID’s (Veeam):
- Bron van gebeurtenis: Veeam Agent
- Gebeurtenis-ID’s: 190
- Tekst bevat: mislukt
- Voorbeeld van bron/ID’s (Acronis):
- Bron van gebeurtenis: online back-upsysteem
- Gebeurtenis-ID: 1
- Tekst bevat: mislukt
4 sleutels om uw monitoring naar het volgende niveau te tillen
- Maak een basissjabloon voor de monitoring van de conditie van het apparaat.
- Praat met klanten over hun prioriteiten.
- Welke servers en werkstations zijn belangrijk?
- Wat zijn hun kritische line-of-business- of productiviteitsapplicaties?
- Waar liggen hun IT-pijnpunten?
- Monitor uw PSA/ticketingsysteem op terugkerende problemen.
- Pas het alertingsysteem aan om ruis op de tickets te voorkomen.
- Monitor de gebeurtenislogs van klanten op terugkerende problemen.
Ticketing en beste praktijken rond alerting
- Waarschuw alleen voor actiegerichte informatie. Als u geen specifieke reactie hebt voor een bepaalde monitoring, monitor dat dan niet.
- Deel uw waarschuwingen in zodat u naar verschillende serviceborden in uw PSA kunt gaan op basis van het type of de prioriteit.
- Houd regelmatig vergaderingen over waarschuwingen om het volgende te bespreken:
-
- Welke waarschuwingen veroorzaken het meeste ruis? Kunnen ze worden verwijderd of worden beperkt?
- Wat wordt niet gemonitord of creëert meldingen die wel gemonitord zouden moeten worden?
- Welke veel voorkomende waarschuwingen kunnen automatisch worden verholpen?
- Zijn er aanstaande projecten die waarschuwingen kunnen genereren?
- Ruim uw tickets en waarschuwingen op als ze opgelost zijn.
-
- Veel voorwaardes hebben in NinjaOne een ‘Reset wanneer niet langer waar’ of ‘Reset wanneer niet waar gedurende x periode’ ter ondersteuning bij de oplossing en opruiming van meldingen die zichzelf kunnen oplossen.
Meer MSP-monitoringideeën
Bekijk de uitstekende serie van Kelvin Tegelaar (in het Engels) over monitoring op afstand met PowerShell. Kelvin bekijkt hoe u alles kunt monitoren, van netwerkverkeer tot de conditie van een active directory tot mislukte aanmeldpogingen bij Office 365, Shodan-resultaten en nog veel meer. En hij deelt ook de PowerShell-scripts die zijn ontworpen voor een agnostisch RMM. U kunt ook onze blogpost lezen over de verschillen tussen PowerShell vs. CMD Prompt (in het Engels) en het gebruik ervan.
In onze wekelijkse MSP Bento-nieuwsbrief publiceren we regelmatig de blogberichten van Kelvin Tegelaar en tal van aanvullende tools en hulpmiddelen (in het Engels). Schrijf u nu in om de laatste editie te ontvangen, samen met een speciale lijst van de populairste tools en hulpmiddelen die we hebben gedeeld.






